Intro
So for work I have built a tool that takes advantage of multithreaded processes on python. When researching for this topic I came across a number of guides that suggest the usage of the `threading <https://docs.python.org/3/library/threading.html>`__ module. Now don't get me wrong, the threading module is great, but do to a limitation with the Global Interpreter Lock when you're doing lot's of actual data crunching you can run into issue. Here's the quote straight from the manual :
CPython implementation detail: In CPython, due to the Global Interpreter Lock, only one thread can execute Python code at once (even though certain performance-oriented libraries might overcome this limitation). If you want your application to make better use of the computational resources of multi-core machines, you are advised to use multiprocessing or concurrent.futures.ProcessPoolExecutor. However, threading is still an appropriate model if you want to run multiple I/O-bound tasks simultaneously.
So I started to research how to use the multiprocessing module, read a whole heap on it and built my application for work using it. Across the way I ran into several great tutorials on the multiprocessing module. Most of them used multiprocessing's Pool module which is great. And you should always attempt to use it. However I found myself asking questions about how threads were running, wanting to do introspection and other things that made managing threads manually of greater benefit to me. So I wrote up a version of my code that doesn't use the thread pool but still keeps track of what's going on. I figured I'd write up an example of what I found so that the Internet can enjoy or ignore it per usual and hopefully someone get's some use out of it.
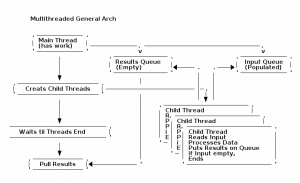
Solution/Arch
So how to use multiprocessing was of course the next question. Multiprocessing looks a lot like the threading module so a lot of the primitives are there. The issues come when you have long processes and you want to introspect what's happening. Because threading runs one at a time it becomes very easy to share data between running processes in multiprocessing it becomes a bit harder as a number of the shared memory features don't work or are unavailable. Luckily the multiprocessing module provides you a queuing interface that is quite similar to how the queue works on the normal threading module.
There is a general pattern I've started using to process jobs multithreaded. An input queue, results queue and a series of identical workers will pull work off the queue, process it and place the results on the result queue. After I've provisioned my threads I then poll all of my worker threads periodically to see if they've completed. Once they have I have my main process grab all the results off of the results queue and display them back to the screen (or generally kick off the next thing).
Implementation
So onto the code. For reference all of my code is available here on my github. So the main juice of the code is the work being done. In my example I'm taking a string and hashing it 1,000,000 times with sha512 (using the hashlib library). You're code probably isn't doing this so this module will be where you place your own custom code. I'm then returning a dictionary that contains the original string and is hashed value. If your workstation is significantly slower or faster than mine you may need to adjust the amount of times you hash the value.
Function process_one_thread :
def process_one_thread(uuidtohash="nostring?", num=1000000) : # This will be our stand in process for doing a cpu intensive task # It generates a randomish string and hashes it 1000000 times. # This is done to simulate a single threaded load on my workstation # this takes about 25 seconds (for all 16) you may need to lower it or raise it # to make the example work. current_hash = uuidtohash.encode() for i in range(0,num) : # Hash it hashobject = hashlib.sha512(current_hash).hexdigest().encode() current_hash = hashobject return_dict = { uuidtohash : hashobject.decode() } return return_dict
So now that we have the worker code. We want to make a bit of code that calls that manages the input output. I call this dequeue_work. It's general purpose is to continually read input values off of the queue until the queue then process the input with the worker code. Then it takes the output from that and place it on the results queue. When there's no more work, it kills itself off.
Function dequeue_work :
def dequeu_work(thread_number, work_queue, result_queue) : while True : if work_queue.empty() == False : # Get Work this_work = work_queue.get(timeout=3) # Process Work this_result = process_one_thread(uuidtohash=this_work) # Store result result_queue.put(this_result) else : # No More work on the queue breaking loop break my_pid = multiprocessing.current_process().pid # Kill myself as I'm no longer needed os.kill(my_pid, signal.SIGKILL)
So the two functions above are going to make up the entirety of your child processes. Now were going to go over how to call and manage the threads. In my example I started by defining some constants (that in your code should definitely be called by a config file from somewhere). I create a manager object and define an input and output queue :
Snippet Creating Queues :
# Multiprocess Items manager = multiprocessing.Manager() # Create a Queue for data to Live in work_queue = manager.Queue(maxsize=0) # Results Queue result_queue = manager.Queue()
Then I go ahead and populate my input queue with work. This is purley meaningless input, your input shoudl probably be application Ispecific in the future :
Snippet Populating Work :
for i in range(0,RESULTS_WANTED): work_queue.put(str(uuid.uuid4()))
Provisioning threads is the next step. Essentially I'm going to create a dict that I call an array because I'm a bad programmer. I'm going to cycle through the amount of threads I want and provision a thread using the dequeue_work function we defined above. I'm going to then daemonize & start said thread. Additionally I have some logic of what to do if there's no more work left in the queue.
Snippet Provisioning Threads :
for thread_count in range(0, THREADS) : if work_queue.empty() == False : # Queue Isn't Empty Turn this on to debug it's useful. :) #print("Provisioning thread ", str(thread_count)) # Provision Thread thread_array[thread_count] = multiprocessing.Process(target=dequeu_work, \ args=(thread_count, work_queue, result_queue) ) # Daemonize it thread_array[thread_count].daemon = True # Start my This Thread thread_array[thread_count].start() else : # Work Queue is Prematurely Empty print("Queue is empty at ", str(thread_count), " threads prematurely stopping thread allocation.") break
The key part of the snippet above is the new Process creation :
thread_array[thread_count] = multiprocessing.Process(target=dequeu_work, \ args=(thread_count, work_queue, result_queue) )
There are a number of options that one can pass to the new Process but this will provision a new thread with the code we mentioned above.
Because the multiprocessing module doesn't have an equivalent to the threadpool moduel we can't just sit and wait for the threads to come back (it does have the dummy module but I haven't had a chance to use it additionally there's an ThreadPoolExecutor module from concurrent.futures that I also haven't had a chance to loose), we instead are going to do a while/sleep loop to check if the processes are done. The good news is that here you could add code to implement timeouts, statistics and other custom runtime data that you wish to grab.
Snippet Waiting for Threads to End :
# Now we wait for my threads to endtime while True : any_thread_alive = False for thread in thread_array.keys() : if thread_array[thread].is_alive() == True : any_thread_alive = True if any_thread_alive : # Threads still alive sleep 5 seconds and check again time.sleep(5) pass else : # Threads Done End While Loop break
And finally the last and most important part. Now you can grab the results from your threads. Essentially you only need to cycle through the result_queue and grab said results :
Snippet Grabbing Results :
# Grab Results for i in range(0, result_queue.qsize()) : this_result = result_queue.get(timeout=5) # Place on Results Queue results_dict["data"].append(this_result)
Results
So in the repo there's two files, example_multi_thread.py & example_single_thread.py. The single threaded version of this task (on my workstation, results may vary) completes in 25(ish)s. The multthreaded version of this ends in about 15s (and could likely be faster with more optimizations).
Snippet Super-unscientific timings :
> ./example_single_thread.py | jq '.totaltime_in_s' 26 > ./example_multi_thread.py | jq '.totaltime_in_s' 15
It's harder to show in a blog post, but if you run this while running htop you can see it peg out multiple cpu/cores in the second version but not do so in the first.
Scaling this Up
More Work
Truth is that a process shaving 10s off it's run time is not always a big deal. Generally for production you're going to want to have to scale farther than this. In that model making a "never ending" version of the workers combine with a more featureful queuing software that can operate in a multi-host environment is probably your best bet for scaling up. On the application I run we can scale this model up only so far on a single host and that limit is easy to reach (especially if your application is compute heavy). So if you've got a big chunk of work to run do consider something like RabbitMQ or ZeroMQ. And if you're having trouble deciding using something like Queues.io to get a feel for your options.
Debugging
sys.stdout.flush() can really be your friend. Yes it can cause locking (so make it available as a debug option) but being able to log what's happening to your code behind the scenes can help you figure out what's wrong much quicker than otherwise could be enabled. Additionally, considered a second performance queue. There you can place running statistics that your main process can serve up; allowing some level of introspection.
And finally, catch your errors. Errors in multithreaded programs can be weird. You definitely want to catch them and "do the right thing." In my current app I spent way to much time finding weird unexpected errors based on bad and unexpected data.
Simultaneous Processing
If your data comes in regularly consider redesigning the "get work" part of this code to start allocating threads as the data is coming in. This will be especially useful if you're trying to design an "always on/always processing" system.
Conclusions
I hope this was a helpful introduction into the threading model and a simple example of how to do multithreading in Python that doesn't suffer from the global interpreter lock. If possible you should always try to use the pool module but if you need to do introspection or answer questions about how your code is running. Doing it this way may offer you more "bang for your buck." Additionally you can easily turn this process into an always on, multithreaded daemon for when it comes time to scale it up.
References
- Tutorials Point. "Python Multithreaded Programming."
- A good tutoriall using the thread module that would suffer from issues with the Global Interpreter Lock.
- Kiehl, Chris. "Parallelism in one line."
- A great tutorial that also uses the thread module.
- Raschka, Sebastian. "An introduction to parallel programming using Python's multiprocessing module."
- The tutorial you probably should be reading on the multiprocessing module.